Tool access
Which tools can the agent call, what arguments did it pass, and which calls should have required approval?
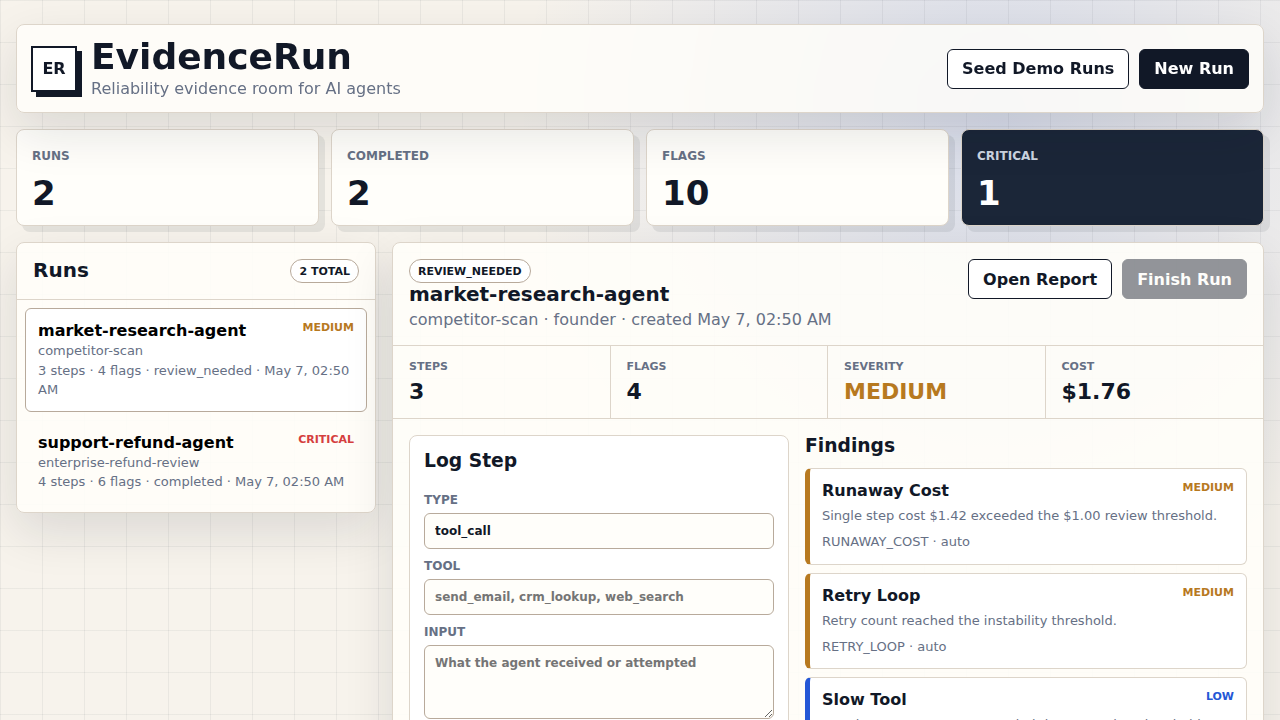
Reliability evidence for AI-agent startups
EvidenceRun instruments one agent workflow, maps failures against a 12-mode taxonomy, and delivers a buyer-ready reliability report founders can use in investor, security, and enterprise conversations.
The deliverable
Twelve failure modes, mapped to evidence from your traces, with severity, remediation class, and a non-certification disclaimer. Hand it to a buyer's diligence team and the conversation moves.
The 12-mode taxonomy
Every report maps observed behavior against the same twelve modes — so a buyer's security team can compare findings across vendors, and you can answer the same question every time.
Deal killers
Customer data, secrets, or prompt content leak to a third-party tool, log, or downstream model.
High-impact actions execute without the human-in-the-loop check the workflow promises.
A decision was made; nobody can reconstruct what the agent saw, asked, or weighed.
Inputs, prompts, model versions, and tool outputs are not stored long enough for an after-the-fact audit.
Ops nightmares
Agent calls a tool with the wrong args, wrong scope, or no need to call it at all.
Silent retry loops on non-idempotent calls cause duplicate side effects nobody can see in the trace.
Recursive calls, retry storms, or context bloat send a single run past the alarm threshold.
Tool returned an error, the agent returned success — the user is told something happened that didn't.
Long-tail risks
Untrusted content in inputs, attachments, or web pages overrides system instructions.
Agent acts on cached customer state, expired session data, or out-of-date documents.
Agent inherits service-account permissions far beyond what the workflow requires.
Customer-facing wording, format, or recommendations drift across runs in ways nobody noticed.
What gets audited
Which tools can the agent call, what arguments did it pass, and which calls should have required approval?
Where did customer data, PII, secrets, prompts, and third-party API payloads move during the run?
Can the team reconstruct what the agent saw, tried, changed, failed, retried, and claimed afterward?
Pilot offer
Pick one agent workflow that matters for sales, support, finance, coding, research, or operations.
Share traces, logs, prompts, tool calls, screenshots, or run a short screen-share walkthrough.
Receive an Agent Reliability Report: failure taxonomy mapping, evidence examples, and remediation backlog.
For startups building AI agents that need to look serious in front of investors, security teams, or enterprise buyers.
EvidenceRun reports are reliability evidence for product, security, and investor conversations. Not a legal compliance certification or safety guarantee.